
npm cache clean -f sudo npm install -g n sudo n stable node --version node app.js
Как создать базу данных и пользователя MySQL
Если на вашем сервере не установлена какая-нибудь удобная панель администрирования и вам нужно добавить пользователя и базу данных mysql для создания сайта, сделать это можно через консоль.
Для начала подключитесь к серверу mysql.
# mysql -u root -p
При этом, будет запрошен пароль администратора.
Создаём базу данных:
mysql> CREATE DATABASE `db`;
name замените на имя базы данных.
Следующим шагом будет создание пользователя базы данных. В консоли напечатайте команду:
mysql> CREATE USER 'name'@'localhost' IDENTIFIED BY 'password';
Здесь нужно заменить name на имя пользователя, а password — на пароль для этого пользователя.
Последний шаг — это выдача всех превилегий на базу данных для созданного пользователя. Выполните следующую команду, заменив db на имя базы, a nameна имя пользователя.
mysql> GRANT ALL PRIVILEGES ON `db`.* TO 'name'@'localhost';
Обновите превилегии командой:
mysql> FLUSH PRIVILEGES;
Добавление пользователя в группу
sudo usermod -a -G www-data username
WebUsb API
С помощью технологии WebUsb API можно осуществлять подключения к usb -устройствам которые находятся на компьютере (Пример можно скачать по ссылке снизу).
!!! Внимание. Перед использованием примеров нужно убедиться, что adb отключено
adb kill-server
!!! Внимание. В примере кода явно вбит vendorId, его нужно заменить на требуемый.
Adb.WebUSB.Transport.open = function() {
// было так
// let filters = [
// { classCode: 255, subclassCode: 66, protocolCode: 1 },
// { classCode: 255, subclassCode: 66, protocolCode: 3 }
// ];
let filters = [{
vendorId: '2821'
}];
return navigator.usb.requestDevice({ filters: filters })
.then(device => device.open()
.then(() => new Adb.WebUSB.Transport(device)));
};
Чтобы узнать vendorId выполните следующий пример узнать vendorId
Запускаем наш пример.
Подключаем устройство по кабелю (нужно убедиться чтобы отладка по USB кабелю была включена).
Пример можно скачать отсюда.
Полезные ссылки:
- https://github.com/webadb/webadb.js — библиотека
- https://github.com/webadb/webadb.github.io — пример подключения
- https://chrome.google.com/webstore/detail/web-server-for-chrome/ofhbbkphhbklhfoeikjpcbhemlocgigb — расширение для Chrome, чтобы создавать web-сервер
- https://developers.google.com/web/updates/2016/03/access-usb-devices-on-the-web — статья с описанием
Перенаправление запроса в Nginx
Если нужно сделать перенаправление с одной страницы (псевдонима) на другую страницу нужно добавить следующий код в настройки сайта
server {
...
location = /имя {
rewrite ^/.* http://localhost permanent;
}
...
}
Сжатие JS-файлов
Для создание одного js-файлай из нескольких можно использовать утилиту от Google — Closure Compiler
- устанавливаем Java Runtime Environment version 7, если у Вас её нет
- Скачиваем файл compiler.jar
- Распаковываем в папку например e:\compressionjs
- Для примера создаем в этой папке js — файл (например simple.js)
|
1
2
3
4
5
|
// A simple function.function hello(longName) { alert('Hello, ' + longName);}hello('New User'); |
5. Выполняем команду java -jar compiler.jar —js sample.js —js_output_file hello-compiled.js
Примечание: Если нужно по всей папке собрать, то можно выполнить java -jar compiler.jar —js=»*.js» —js_output_file hello-compiled.js
Подробнее о командах можно узнать java -jar compiler.jar —help
Закрыть окно merge_msg
It’s not a Git error message, it’s the editor as git uses your default editor.
To solve this:
- press «i»
- write your merge message
- press «esc»
- write «:wq»
- then press enter
Короткий справочник по git командам
Решил собрать небольшой справочник по git командам, чтобы можно было просто и легко освежить у себя в памяти то что когда-то использовалось.
*Основы*
Настройка Git клиента для идентификации пользователя:
git config –global user.name “Your Name”
git config –global user.email “your@email.address”
git config –global core.editor “your editor”
Инициализация репозитория в текущем каталоге:
git init
Создает репозиторий в указанном каталоге:
git init <directory>
Клонирование репозитория на локальную машину:
git clone <repo>
Добавить файл для идексации и следить за всеми изменениями в нем ( можно задавать по маске ):
git add <file>
Добавить каталог для индексации:
git add <directory>
Удалить файл из индексации ( можно задавать по маске ):
git rm <file>
Перенести или переименовать файл / каталог:
git mv <source> <destination>
Сделать “снапшот” всех выполненных изменений:
git commit -a -m “message”
Статус репозитория ( добавление, удаление, изменение файлов ):
git status
Показать историю коммитов:
git log
Показать только определенное количество коммитов:
git log -n <limit>
Показать историю коммитов по конкретному файлу:
git log <file>
Посмотреть различия между последним коммитом и текущими изменениями:
git diff
Просмотр всех различий между коммитами:
git diff <commit> <commit>
Посмотреть различия между коммитом и текущими изменениями:
git diff <commit> <file>
Посмотреть различия между коммитами для файла:
git diff <commit> <commit> <file>
Показать список всех файлов в основной ветке:
git ls-tree master -r –name-only
*Работа с ветками*
Список веток:
git branch
Создание ветки:
git branch <new_branch_name>
Безопастное удаление ветки, если не были сделаны изменения:
git branch -d <branch_name>
Удаление ветки, даже если были сделаны изменения:
git branch -D <branch_name>
Переименование текущей ветки:
git branch -m <rename_current_branch>
Отмена изменений в локальном файле
git checkout FETCH_HEAD — — <file>
Переход к существующей ветке:
git checkout <branch_name>
Создание и переход к ветке:
git checkout -b <new_branch_name>
Слияние текущей ветки с указанной:
git merge <branch>
*Откат изменений*
Перейти на последний коммит ветки “master”:
git checkout master
Откатить изменения во всех файлах до указанного коммита:
git checkout <commit>
Откатить изменения для конкретного файла до указанного коммита:
git checkout <commit> <file>
Сделать откат всех изменений выполненных в коммите, при этом создается новый коммит указывающий на откат изменений:
git revert <commit>
Отмена изменений до последнего коммита, а также сбрасывает индексацию для конкретного файла:
git reset HEAD <file>
Отмена изменений до последнего коммита и сбрасывает индексацию:
git reset –soft
Отмена изменений до последнего коммита, сбрасывает индексацию, а так же отменить любые изменения в рабочей директории:
git reset –hard
programming Удаляет файлы которые не были добавлены в репозиторий:
git clean -f
Удаляет файлы которые не были добавлены в репозиторий по указанному пути:
git clean -f <path>
Удаляет файлы и каталоги которые не были добавлены в репозиторий:
git clean -df
Только показывает, что будет удаленно:
git clean -n
*Работа с удаленными репозиториями*
Список соединений с удаленными репозиториями:
git remote
Добавить соединение:
git remote add <name> <url>
Удалить соединение:
git remote rm <name>
Переименовать соединение:
git remote rename <old_name> <new_name>
Получить изменения из репозитория со списком всех веток ( при этом стираются любые локальные изменения ):
git fetch <remote>
Получить изменения из репозитория для конкретной ветки ( при этом стираются любые локальные изменения ):
git fetch <remote> <branch>
Получить копию текущей ветки с удаленного репозитория и слить ее с локальной копией:
git pull <remote>
Залить указанную ветку на удаленный репозиторий:
git push <remote> <branch>
И напоследок несколько ссылок где можно найти более подробное руководство по git:
Перестаем бояться виртуализации при помощи KVM
Мне лично проще всего думать о KVM (Kernel-based Virtual Machine), как о таком уровне абстракции над технологиями хардверной виртуализации Intel VT-x и AMD-V. Берем машину с процессором, поддерживающим одну из этих технологий, ставим на эту машину Linux, в Linux’е устанавливаем KVM, в результате получаем возможность создавать виртуалки. Так примерно и работают облачные хостинги, например, Amazon Web Services. Наряду с KVM иногда также используется и Xen, но обсуждение этой технологии уже выходит за рамки данного поста. В отличие от технологий контейнерной виртуализации, например, того же Docker, KVM позволяет запускать в качестве гостевой системы любую ОС, но при этом имеет и большие накладные расходы на виртуализацию.
Примечание: Описанные ниже действия были проверены мной на Ubuntu Linux 14.04, но по идее будут во многом справедливы как для других версий Ubuntu, так и других дистрибутивов Linux. Все должно работать как на десктопе, так и на сервере, доступ к которому осуществляется по SSH.
Установка KVM
Проверяем, поддерживается ли Intel VT-x или AMD-V нашим процессором:
grep -E ‘(vmx|svm)’ /proc/cpuinfo
Если что-то нагреполось, значит поддерживается, и можно действовать дальше.
Устанавливаем KVM:
sudo apt-get update
sudo apt-get install qemu-kvm libvirt-bin virtinst bridge-utils
sudo apt-get install qemu-kvm libvirt-bin virtinst bridge-utils
Что где принято хранить:
- /var/lib/libvirt/boot/ — ISO-образы для установки гостевых систем;
- /var/lib/libvirt/images/ — образы жестких дисков гостевых систем;
- /var/log/libvirt/ — тут следует искать все логи;
- /etc/libvirt/ — каталог с файлами конфигурации;
Теперь, когда KVM установлен, создадим нашу первую виртуалку.
Создание первой виртуалки
В качестве гостевой системы я выбрал FreeBSD. Качаем ISO-образ системы:
cd /var/lib/libvirt/boot/
sudo wget http://ftp.freebsd.org/path/to/some-freebsd-disk.iso
sudo wget http://ftp.freebsd.org/path/to/some-freebsd-disk.iso
Управление виртуальными машинами в большинстве случаев производится при помощи утилиты virsh:
sudo virsh —help
Перед запуском виртуалки нам понадобится собрать кое-какие дополнительные сведения.
Смотрим список доступных сетей:
sudo virsh net-list
Просмотр информации о конкретной сети (с именем default):
sudo virsh net-info default
Смотрим список доступных оптимизаций для гостевых ОС:
sudo virt-install —os-variant list
Итак, теперь создаем виртуальную машину с 1 CPU, 1 Гб RAM и 32 Гб места на диске, подключенную к сети default:
sudo virt-install \
—virt-type=kvm \
—name freebsd10 \
—ram 1024 \
—vcpus=1 \
—os-variant=freebsd8 \
—hvm \
—cdrom=/var/lib/libvirt/boot/FreeBSD-10.2-RELEASE-amd64-disc1.iso \
—network network=default,model=virtio \
—graphics vnc \
—disk path=/var/lib/libvirt/images/freebsd10.img,size=32,bus=virtio
—virt-type=kvm \
—name freebsd10 \
—ram 1024 \
—vcpus=1 \
—os-variant=freebsd8 \
—hvm \
—cdrom=/var/lib/libvirt/boot/FreeBSD-10.2-RELEASE-amd64-disc1.iso \
—network network=default,model=virtio \
—graphics vnc \
—disk path=/var/lib/libvirt/images/freebsd10.img,size=32,bus=virtio
Вы можете увидеть:
WARNING Unable to connect to graphical console: virt-viewer not
installed. Please install the ‘virt-viewer’ package.Domain installation still in progress. You can reconnect to the console
to complete the installation process.
installed. Please install the ‘virt-viewer’ package.Domain installation still in progress. You can reconnect to the console
to complete the installation process.
Это нормально, так и должно быть.
Затем смотрим свойства виртуалки в формате XML:
sudo virsh dumpxml freebsd10
Тут приводится наиболее полная информация. В том числе есть, к примеру, и MAC-адрес, который понадобятся нам далее. Пока что находим информацию о VNC. В моем случае:
<graphics type=‘vnc’ port=‘5900’ autoport=‘yes’ listen=‘127.0.0.1’>
С помощью любимого клиента (я лично пользуюсь Rammina) заходим по VNC, при необходимости используя SSH port forwarding. Попадаем прямо в инстялятор FreeBSD. Дальше все как обычно — Next, Next, Next, получаем установленную систему.
Основные команды
Давайте теперь рассмотрим основные команды для работы с KVM.
Получение списка всех виртуалок:
sudo virsh list —all
Получение информации о конкретной виртуалке:
sudo virsh dominfo freebsd10
Запустить виртуалку:
sudo virsh start freebsd10
Остановить виртуалку:
sudo virsh shutdown freebsd10
Жестко прибить виртуалку (несмотря на название, это не удаление):
sudo virsh destroy freebsd10
Ребутнуть виртуалку:
sudo virsh reboot freebsd10
Склонировать виртуалку:
sudo virt-clone -o freebsd10 -n freebsd10-clone \
—file /var/lib/libvirt/images/freebsd10-clone.img
—file /var/lib/libvirt/images/freebsd10-clone.img
Включить/выключить автозапуск:
sudo virsh autostart freebsd10
sudo virsh autostart —disable freebsd10
sudo virsh autostart —disable freebsd10
Запуск virsh в диалоговом режиме (все команды в диалоговом режиме — как описано выше):
sudo virsh
Редактирование свойств виртуалки в XML, в том числе здесь можно изменить ограничение на количество памяти и тд:
sudo virsh edit freebsd10
Важно! Комментарии из отредактированного XML, к сожалению, удаляются.
Когда виртуалка остановлена, диск тоже можно ресайзить:
sudo qemu-img resize /var/lib/libvirt/images/freebsd10.img -2G
sudo qemu-img info /var/lib/libvirt/images/freebsd10.img
sudo qemu-img info /var/lib/libvirt/images/freebsd10.img
Важно! Вашей гостевой ОС, скорее всего, не понравится, что диск внезапно стал больше или меньше. В лучшем случае, она загрузится в аварийном режиме с предложением переразбить диск. Скорее всего, вы не должны хотеть так делать. Куда проще может оказаться завести новую виртуалку и смигрировать на нее все данные.
Резервное копирование и восстановление производятся довольно просто. Достаточно сохранить куда-то вывод dumpxml, а также образ диска, а потом восстановить их. На YouTube удалось найти видео с демонстрацией этого процесса, все и вправду несложно.
Настройки сети
Интересный вопрос — как определить, какой IP-адрес получила виртуалка после загрузки? В KVM это делается хитро. Я в итоге написал такой скрипт на Python:
#!/usr/bin/env python3
# virt-ip.py script
# (c) 2016 Aleksander Alekseev
# http://eax.me/
import sys
import re
import os
import subprocess
from xml.etree import ElementTree
def eprint(str):
print(str, file=sys.stderr)
if len(sys.argv) < 2:
eprint(«USAGE: « + sys.argv[0] + » <domain>»)
eprint(«Example: « + sys.argv[0] + » freebsd10″)
sys.exit(1)
if os.geteuid() != 0:
eprint(«ERROR: you shold be root»)
eprint(«Hint: run `sudo « + sys.argv[0] + » …`»);
sys.exit(1)
if subprocess.call(«which arping 2>&1 >/dev/null», shell = True) != 0:
eprint(«ERROR: arping not found»)
eprint(«Hint: run `sudo apt-get install arping`»)
sys.exit(1)
domain = sys.argv[1]
if not re.match(«^[a-zA-Z0-9_-]*$», domain):
eprint(«ERROR: invalid characters in domain name»)
sys.exit(1)
domout = subprocess.check_output(«virsh dumpxml «+domain+» || true»,
shell = True)
domout = domout.decode(‘utf-8’).strip()
if domout == «»:
# error message already printed by dumpxml
sys.exit(1)
doc = ElementTree.fromstring(domout)
# 1. list all network interfaces
# 2. run `arping` on every interface in parallel
# 3. grep replies
cmd = «(ifconfig | cut -d ‘ ‘ -f 1 | grep -E ‘.’ | « + \
«xargs -P0 -I IFACE arping -i IFACE -c 1 {} 2>&1 | « + \
«grep ‘bytes from’) || true»
for child in doc.iter():
if child.tag == «mac»:
macaddr = child.attrib[«address»]
macout = subprocess.check_output(cmd.format(macaddr),
shell = True)
print(macout.decode(«utf-8»))
Скрипт работает как с default сетью, так и с bridged сетью, настройку которой мы рассмотрим далее. Однако на практике куда удобнее настроить KVM так, чтобы он всегда назначал гостевым системам одни и те же IP-адреса. Для этого правим настройки сети:
sudo virsh net-edit default
… примерно таким образом:
<dhcp>
<range start=‘192.168.122.2’ end=‘192.168.122.254’/>
<!— добавляем вот эту строчку: —>
<host mac=’52:54:00:59:96:00′ name=‘freebsd10’ ip=‘192.168.122.184’/>
</dhcp>
<range start=‘192.168.122.2’ end=‘192.168.122.254’/>
<!— добавляем вот эту строчку: —>
<host mac=’52:54:00:59:96:00′ name=‘freebsd10’ ip=‘192.168.122.184’/>
</dhcp>
После внесения этих правок необходимо выполнить команды:
sudo virsh net-destroy default
sudo virsh net-start default
sudo service libvirt-bin restart
sudo virsh net-start default
sudo service libvirt-bin restart
Теперь перезагружаем несколько раз гостевую систему и убеждаемся, что она всегда получает адрес 192.168.122.184.
По умолчанию виртуальные машины могут ходить в интернет, а также к ним можно приконнектится из хост-системы. В общем и целом все выглядит так, словно гостевые системы находятся за NAT. На практике же часто бывает куда удобнее иметь bridged сеть. Как она настраивается на хост-системе ранее мы уже рассматривали в заметках Туториал по контейнеризации при помощи LXCи Контейнерная виртуализация при помощи OpenVZ.
После окончания настройки правим конфиг гостевой системы. Находим в нем что-то вроде:
<interface type=‘network’>
<source network=‘default’/>
<!— остальное не важно —>
</interface>
<source network=‘default’/>
<!— остальное не важно —>
</interface>
… и заменяем на что-то вроде:
<interface type=‘bridge’>
<source bridge=‘br0’/>
<!— прочее оставляем как есть —>
</interface>
<source bridge=‘br0’/>
<!— прочее оставляем как есть —>
</interface>
Перезагружаем гостевую систему и проверяем, что она получила IP по DHCP от роутера. Если же вы хотите, чтобы гостевая система имела статический IP-адрес, это настраивается как обычно внутри самой гостевой системы.
Программа virt-manager
Вас также может заинтересовать программа virt-manager:
sudo apt-get install virt-manager
sudo usermod -a -G libvirtd USERNAME
sudo usermod -a -G libvirtd USERNAME
Так выглядит ее главное окно:
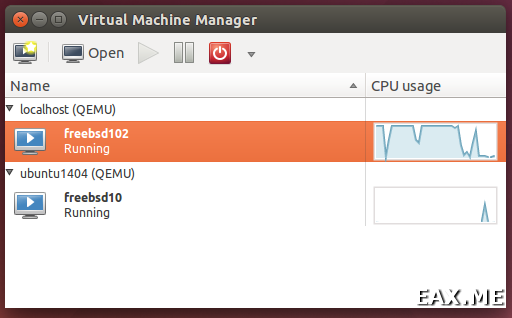
Как видите, virt-manager представляет собой не только GUI для виртуалок, запущенных локально. С его помощью можно управлять виртуальными машинами, работающими и на других хостах, а также смотреть на красивые графички в реальном времени. Я лично нахожу особенно удобным в virt-manager то, что не нужно искать по конфигам, на каком порту крутится VNC конкретной гостевой системы. Просто находишь виртуалку в списке, делаешь двойной клик, и получаешь доступ к монитору.
Еще при помощи virt-manager очень удобно делать вещи, которые иначе потребовали бы трудоемкого редактирования XML-файлов и в некоторых случаях выполнения дополнительных команд. Например, переименование виртуальных машин, настройку CPU affinity и подобные вещи. Кстати, использование CPU affinity существенно снижает эффект шумных соседей и влияние виртуальных машин на хост-систему. По возможности используйте его всегда.
Если вы решите использовать KVM в качестве замены VirtualBox, примите во внимание, что хардверную виртуализацию они между собой поделить не смогут. Чтобы KVM заработал у вас на десктопе, вам не только придется остановить все виртуалки в VirtualBox и Vagrant, но и перезагрузить систему. Я лично нахожу KVM намного удобнее VirtualBox, как минимум, потому что он не требует выполнять команду sudo /sbin/rcvboxdrv setup после каждого обновления ядра, адекватно работает c Unity, и вообще позволяет спрятать все окошки.
Заключение
По традиции, немного ссылок по теме:
В целом, KVM произвел на меня исключительно положительное впечатление. Теперь я не понимаю, зачем все это время я мучился с Vagrant и VirtualBox, когда все уже есть в KVM и сделано куда лучше. Ну, почти. Кое-какие косяки все же имеются. Так, например, в htop гостевой системы вы можете видеть, что утилизируете CPU на 30%, хотя на хост-системе вы утилизируете все 100%. Однако мой опыт работы с виртуальными машинами свидетельствует о том, что такого рода проблемы и прочие шумные соседи возникают всегда, и еще один минорный баг в общем-то не делает в этом плане все сильно хуже.
Работа с HDD
Информация о свободном месте на жестком диске. Параметр -h нужен чтобы выводить форматирование.
df -h
Информация о размере папки.
du /var/www
Информация об установленном диске.
hdparm -Ii /dev/sda1