Запустите терминал.
Подключите репозиторий deadsnakes со всеми версиями Python.

sudo add-apt-repository ppa:deadsnakes/ppaУстановите Python 3.9:

sudo apt-get install python3.9Рассказываю сложные вещи простыми словами
Запустите терминал.
Подключите репозиторий deadsnakes со всеми версиями Python.
sudo add-apt-repository ppa:deadsnakes/ppaУстановите Python 3.9:
sudo apt-get install python3.9Для создания виртуального окружения, перейдите в директорию своего проекта и выполните:
python -m venv venv-m — флаг для запуска venv как исполняемого модуля.
venv — название виртуального окружения (где будут храниться ваши библиотеки).
В результате будет создан каталог venv/ содержащий копию интерпретатора Python, стандартную библиотеку и другие вспомогательные файлы. Все новые пакеты будут устанавливаться в venv/lib/python3.x/site-packages/.
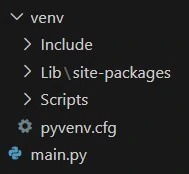
Активация
Чтобы начать пользоваться виртуальным окружением, необходимо его активировать:
venv\Scripts\activate.bat — для Windows;source venv/bin/activate — для Linux и MacOS.source выполняет bash-скрипт без запуска дополнительного bash-процесса.
Проверить успешность активации можно по приглашению оболочки. Она будет выглядеть так:
(venv) root@server:/var/test#Также новый путь до библиотек можно увидеть выполнив команду:
python -c "import site; print(site.getsitepackages())"Автоматическая активация
В некоторых случаях, процесс активации виртуального окружения может показаться неудобным (про него можно банально забыть 🤷♀️).
На практике, для автоматической активации перед запуском скрипта, создают скрипт-обертку на bash:
#!/usr/bin/env bash
source $BASEDIR/venv/bin/activate
python $BASEDIR/my_app.py
Теперь можно установить права на исполнение и запустить нашу обертку:
chmod +x myapp/run.sh
./myapp/run.shДеактивация
Закончив работу в виртуальной среде, вы можете отключить ее, выполнив консольную команду:
deactivateОригинал статьи: https://pythonchik.ru/okruzhenie-i-pakety/virtualnoe-okruzhenie-python-venv
Данный способ позволяет создать скрипт INSERT для наполнения таблицы PostgreSQL.
pg_dump -a -U postgres -t table_name -f output_name.sql --inserts --column-inserts --on-conflict-do-nothing database_nameОписание параметров:
--section=data.pg_dump и не должен существовать ранее.INSERT команд (а не COPY). Это сильно замедлит восстановление; в основном это полезно для создания дампов, которые можно загружать в базы данных, отличные от PostgreSQL. Любая ошибка во время восстановления приведет к потере только строк, которые являются частью проблемной таблицы, INSERT а не всего содержимого таблицы. Обратите внимание, что восстановление может завершиться полным сбоем, если вы изменили порядок столбцов. Опция --column-inserts защищает от изменений порядка столбцов, хотя и работает еще медленнее.INSERT команд с явными именами столбцов (INSERT INTO table (column, ...) VALUES ...). Это сильно замедлит восстановление; в основном это полезно для создания дампов, которые можно загружать в базы данных, отличные от PostgreSQL. Любая ошибка во время восстановления приведет к потере только строк, которые являются частью проблемной таблицы INSERT, а не всего содержимого таблицы.ON CONFLICT DO NOTHING в INSERT. Этот параметр недопустим, если также не указано --inserts, --column-inserts или --rows-per-insert.Пример:
pg_dump -a -U postgres -t dbo.cs_point_types -f cs_point_types.sql --inserts --column-inserts --on-conflict-do-nothing skr-dev-dbСитуация:
Был сделан fork из проекта https://github.com/datalens-tech/datalens. Через некоторое время были внесены изменения, как в исходном проекте, так и в fork-project
Решение:
На локальном компьютере в проекте выполняем команду:
git remote add datalens-tech https://github.com/datalens-tech/datalensГде datalens-tech — это произвольное имя.
Далее выполняем
git fetch datalens-tech
git merge datalens-tech/mainИсправляем конфликты, если они есть.
git pushСохраняем результат
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from transformers import pipeline
MODEL_PATH = "Cleighton071/autotrain-detection-for-product-location-44269111684"
model = AutoModelForSequenceClassification.from_pretrained(MODEL_PATH)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
classifier('i love you')
# [{'label': 'Location', 'score': 0.9967827796936035}]
Читать далее «Использование предобученной модели transformers» На NAS Synology переходим в файловые службы и выбираем NFS
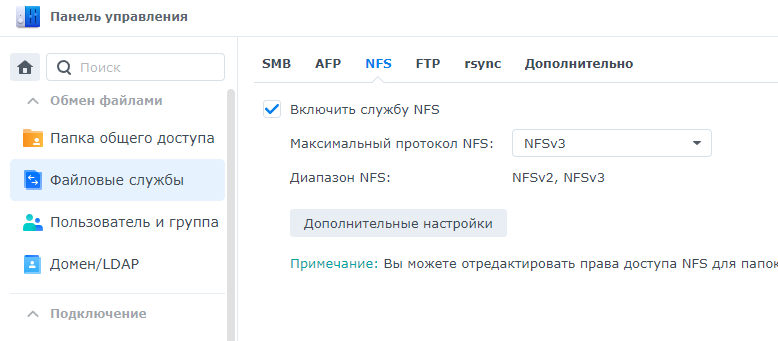
Дальше переходим в пункт Папка общего доступа и создаём папку, например www2
Читать далее «Настройка внешнего хранилища NFS»Инструкция по установке RabbitMQ тут, но для удобства можно запустить docker:
# latest RabbitMQ 3.12 docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.12-management # -it можно заменить на -d
Примечание: доступ к веб-интерфейсу логин guest пароль guest
Читать далее «RabbitMQ & NodeJS»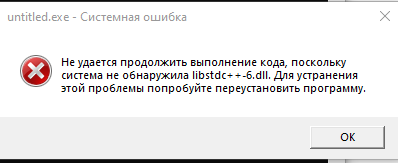
Для решения проблемы требуется добавить путь:
C:\Qt\Qt5.12.12\5.12.12\mingw73_64\binв переменные окружения (на Вашем компе этот путь может быть другим)
После анализа размера папок можно обнаружить, что файл в каталоге:
C:\Users\username\AppData\Local\Docker\wsl\data\ext4.vhdx
занимает значительное пространство.
